Fable 5 vs Opus 4.8: which Claude should you actually pay for
Fable 5 crushes the benchmarks, Opus 4.8 wins the invoice. Real costs, the fallback nobody digs into, and which one to keep in Claude Code.

Updated · 12 min read
The weigh-in
Claude Fable 5 or Claude Opus 4.8: the verdict
Claude Opus 4.8 wins. The rational default for 80% of sessions
- WinnerClaude Opus 4.8
- CategoryModels
The essentials in 30 seconds
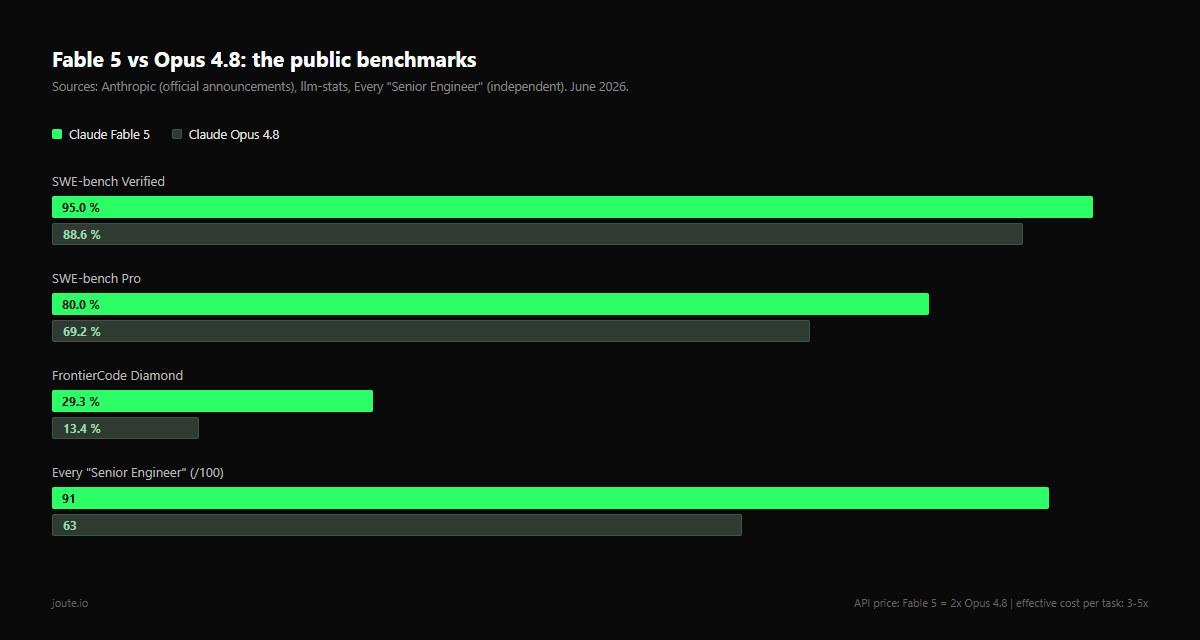
- Fable 5 is the strongest model Anthropic has ever shipped: 95.0% on SWE-bench Verified against 88.6% for Opus 4.8, and 80% on SWE-bench Pro against 69.2%. The gap is real, not marketing.
- It costs exactly twice as much on the API ($10/$50 per million tokens vs $5/$25), but the effective cost per task lands at 3 to 5x because it burns more reasoning tokens. Nobody puts that in the headline.
- On a Claude subscription, Fable 5 eats your usage limits at least twice as fast. We have watched a 5-hour window die in minutes on heavy agentic work.
- There is a trap: on security, bio and chemistry topics, Fable 5 falls back to Opus 4.8. You pay double for the answer the cheaper model would have given you.
- Our verdict: Opus 4.8 stays the daily default. Fable 5 is what you summon when the task would otherwise need a senior engineer for half a day.
Why this comparison exists
Anthropic shipped Opus 4.8 on May 28 and Fable 5 twelve days later, on June 9. Two flagship-priced models, two weeks apart, from the same company. Every benchmark roundup tells you Fable 5 is better. None of them answers the question that actually matters: which one do you set as default in Claude Code, Cursor or Copilot on Monday morning?
We run both daily in Claude Code on our own codebase. Last week Opus 4.8 orchestrated a 15-hour refactoring and audit session across parallel sub-agents on this very site. Fable 5 has been our default since June 10. This comparison comes from that usage plus the published numbers, all sourced and dated, because half of what currently ranks on this query is the launch press release reworded.
| Claude Fable 5 | Claude Opus 4.8 |
|---|---|
 |  |
Scoring, criterion by criterion
Raw capability: Fable 5, clearly. The benchmark spread is unusually wide for a same-family duel: 95.0 vs 88.6 on SWE-bench Verified, 80 vs 69.2 on SWE-bench Pro, 29.3 vs 13.4 on FrontierCode Diamond. Every's independent "Senior Engineer" benchmark scored Fable 5 at 91 against 63 for Opus 4.8. Anthropic's own line is that the longer and more complex the task, the larger Fable 5's lead, and our experience matches: on multi-hour autonomous runs it loses the thread later and recovers better.
Cost: Opus 4.8, and it is not close. The list price says 2x. Reality says more, because Fable 5 thinks longer and writes more tokens for the same instruction. Independent analyses put the effective cost per completed task at 3 to 5x. Simon Willison burned through $110.42 of API credit in a single day of testing. And here is the detail everyone misses: Opus 4.8's Fast mode costs $10/$50, exactly Fable 5's base price. At the same price point you choose between a faster Opus and a smarter Fable, which is a much more honest framing than "2x".
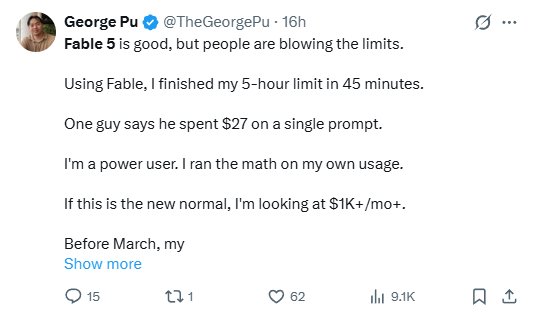
Subscription behavior: Opus 4.8. On Pro and Max plans, Anthropic states Fable 5 consumes your limits about 2x faster. Power users on X report far worse: a $200/month Max plan exhausted in under 30 minutes, a five-hour window dead in 45, one developer citing $27 for a single prompt and projecting four figures a month if he kept Fable as default. Fable 5 is included on paid plans without extra usage credits only until around June 22. After that, every Fable session is a budgeting decision.
The workarounds emerging from the community are worth more than most reviews. The pattern that holds up: Fable 5 as the orchestrator with Opus 4.8 handling the execution-heavy phases, which keeps Fable's planning quality while dodging most of the burn. And per CursorBench data circulating among devs, Fable 5 on low reasoning effort beats Opus 4.8 on max effort while costing less. If you only take one practical thing from this page, take that routing rule.
The fallback: a real asterisk on Fable 5. Fable 5 is the first "Mythos-class" model in general availability, which means it ships with hard classifiers around offensive security, biology and chemistry. When a session trips them, the model degrades to Opus 4.8. At launch this happened silently; after developer backlash, Anthropic switched to a visible fallback notice. Either way the economics are the same: you pay Fable prices for Opus answers. Anthropic says it triggers in under 5% of sessions, but the average hides the distribution. A bug bounty hunter on X reported hitting the fallback on 100% of his actual security-research prompts, and one independent benchmark found 8% of its samples had been quietly answered by Opus 4.8, enough to revise Fable's score downward. Add mandatory 30-day data retention with no zero-retention option, and for security and biotech teams the dealbreaker is structural, not anecdotal.
Capabilities: tie, with nuances. Both carry a 1M-token context window and 128k max output. Both run adaptive thinking rather than the old extended-thinking toggle. Fable 5's vision is the best Anthropic has shipped, to the point of finishing Pokémon FireRed from raw screen pixels. Opus 4.8 remains the stronger computer-use and browser-agent model in Anthropic's own positioning, and it holds the agentic crown on at least one independent test: GPT-5.5 and Opus-class models still beat Fable 5 on the new Agents' Last Exam benchmark. Fable 5 is not uniformly better. It is better at the hard, long, self-directed work.
The full comparison table
| Claude Fable 5 | Claude Opus 4.8 | |
|---|---|---|
| Released | June 9, 2026 | May 28, 2026 |
| API price (in/out per Mtok) | $10 / $50 | $5 / $25 ($10/$50 in Fast mode) |
| Effective cost per task | 3-5x Opus 4.8 | baseline |
| Context / max output | 1M / 128k | 1M / 128k (300k via Batch) |
| SWE-bench Verified | 95.0% | 88.6% |
| SWE-bench Pro | 80.0% | 69.2% |
| FrontierCode Diamond | 29.3% | 13.4% |
| Vision | best Anthropic to date | strong |
| Computer use | strong | Anthropic's strongest |
| Safety fallback | yes, serves Opus 4.8 (visible since backlash) | none |
| Data retention | 30 days, mandatory | standard, zero-retention possible |
| In Claude Code / Cursor / Copilot | yes / yes (day one) / yes (GA June 9) | yes / yes / yes |
| Subscription burn rate | ~2x officially, worse in agentic | baseline |
Verdict by profile
Freelancers
Opus 4.8. Your margin lives and dies on subscription limits, and Fable 5 turns a comfortable Max plan into a stopwatch. Switch to Fable for the one gnarly migration or the legacy codebase nobody understands, then switch back.
Tech leads
Both, with a routing rule. Opus 4.8 as the team default, Fable 5 budgeted per task for the work you would otherwise assign to your most senior engineer for half a day. The teams that win with Fable 5 are the ones that treat it as a specialist, not a default.
Vibe coders
Opus 4.8 without hesitation. On short interactive loops the quality gap barely shows, the speed gap does, and Fast mode exists if you want snappier. Fable 5's advantage compounds over hours of autonomy you are not using.
Security and biotech teams
Read the fallback section twice. Between degradation on your core topics and mandatory 30-day retention, Fable 5 may be structurally wrong for you regardless of how good the model is. Opus 4.8 with zero-retention is the sane option.
A week with both on our own codebase
Our test bench is not a 20-line kata: it is the 4,000-page Next.js monorepo serving the site you are reading. Opus 4.8 orchestrated a 15-hour audit and refactoring session on it, around thirty sub-agents in parallel, without losing the thread or breaking the build once. Fable 5 has been our default since June 10: one-shot planning of large multi-file batches is visibly better, and the quota meter makes you pay for it just as visibly. Our internal routing now mirrors the community pattern: Fable thinks, Opus executes. That is the most honest verdict we can give: both are on the invoice.
Obsolescence risk
Both models live on the frontier treadmill, which is why neither gets a comfortable score here. Opus 4.8 scores 6/10: the Fast mode investment and Anthropic's own "start with Opus" guidance suggest it stays the workhorse tier for a while, the way Sonnet did before it. Fable 5 scores 5/10: it is explicitly the first of a new Mythos class, and the next one will eat it. You are not buying a tool, you are renting the current top of a ladder that grows every quarter. Factor that into any workflow you build around model-specific behavior.
Final verdict
Fable 5 is the better model. Opus 4.8 is the better purchase. We score Fable 5 at 9.4 because the capability jump is genuine and measurable, and Opus 4.8 at 9.1 because it delivers 90% of the outcome at a fraction of the effective cost, without a fallback and without retention strings attached.
Our default in Claude Code is the boring answer: Opus 4.8 for the daily loop, Fable 5 summoned deliberately, per task, with a budget in mind. If your week contains one problem that would genuinely take a senior half a day, that is your Fable 5 ticket, and it is worth every cent of the 3-5x. The rest of the time, the smartest model is the one that does not bill you for thinking it does not need.
Frequently asked questions
Is Fable 5 really worth twice the price of Opus 4.8?
Per token it costs 2x, per completed task more like 3-5x once the extra reasoning tokens are counted. On long autonomous tasks the quality gap justifies it. On everyday coding loops it usually does not.
Why does Fable 5 sometimes answer like a weaker model?
Because it is one, at that moment. On offensive security, biology and chemistry topics, classifiers route you to Opus 4.8, with a visible notice since the developer backlash. Anthropic states this affects under 5% of sessions.
Can I use Fable 5 on a Claude Pro subscription?
Yes. It is included without extra usage credits until around June 22, 2026, after which it draws usage credits billed at API rates. It also consumes plan limits roughly twice as fast as Opus 4.8, and heavy agentic use can be far worse.
Which one should I set in Cursor or GitHub Copilot?
Same logic as Claude Code: Opus 4.8 as the default, Fable 5 per task. Both are available in Cursor since day one and in Copilot since June 9 (policy off by default on Business and Enterprise, and the 30-day retention applies).
Does Fable 5 replace Opus 4.8?
No, and Anthropic says so itself: its docs recommend starting on Opus 4.8 and reaching for Fable 5 when you need the highest available capability. They are tiers, not generations.
Winner: Claude Opus 4.8
The rational default for 80% of sessions.